In denAbschnitten 5.1. und 5.2. hatte ich einige empirische Befunde über strukturelle Defizite in den weißen Fasern bei Stotterern beschrieben. Es handelte sich dabei zum einen um Fasern des SLF, zum anderen um Fasern des ECFS. Nun werde ich ein grobes Modell des linksseitigen Sprachnetzwerkes vorstellen, das diesen beiden Faserbahnen unterschiedliche Funktionen bei der Steuerung des Sprechens zuweist. Das kortikale Netzwerk auf der sprachdominanten (gewöhnlich linken) Hirnhälfte, das die Sprachverarbeitung steuert, lässt sich grob in zwei Bereiche einteilen: in den temporal-/parietalen Teil, der vor allem für die Sprachwahrnehmung zuständig ist, und den frontalen Teil, der hauptsächlich für die Sprachproduktion verantwortlich ist. Allerdings weiß man heute, dass sowohl beim Sprechen als auch beim Verstehen von Sprache beide Bereiche aktiv sind und zusammenwirken.
Dazu sind der temporal-/parietale und der frontale Teil des Netzwerkes über mehrere Bündel von Nervenfasern miteinander verknüpft. Hier lassen sich grob zwei „Hauptwege“ unterscheiden: eine dorsale (obere) und eine ventrale (untere) Faserbahn [15], die jeweils in mehrere einzelne Faserbündel differenziert sind [16]; die Modelle verschiedener Forscher unterscheiden sich in manchen Details. Für unsere Zwecke genügt das grobe Schema, wie es in Abbildung 16 dargestellt ist. Die Abbildung 16 unterscheidet sich äußerlich kaum von der Abbildung 14 im Abschnitt 5.2., doch während es in Abb. 14 um den anatomischen Unterschied zwischen SLF und ECFS geht, geht es in Abb. 16 um einen funktionellen Unterschied.
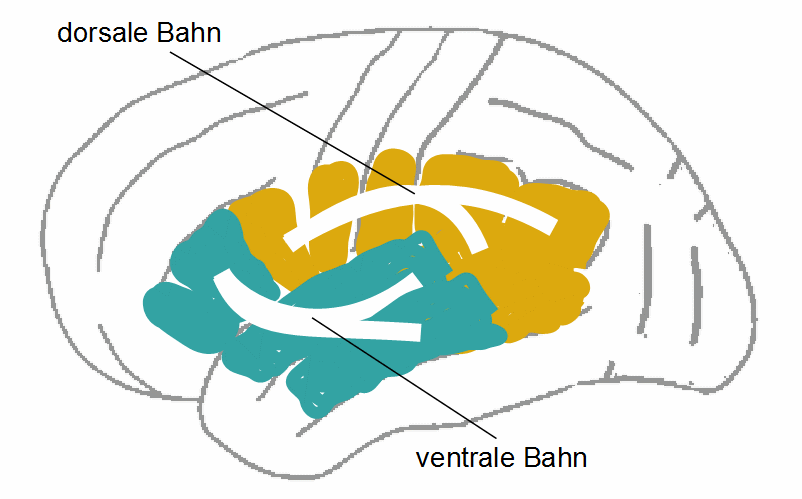
Abbildung 16: Die dorsale Faserbahn verknüpft temporale Regionen, die der phonologischen Verarbeitung dienen, mit motorischen und prämotorischen Regionen, die ventrale Faserbahn verknüpft temporale und frontale Regionen, die mit der semantischen Verarbeitung zu tun haben.
Die dorsale und die ventrale Faserbahn erfüllen unterschiedliche Funktionen, die sich aus den Funktionen der Kortexareale ergeben, die sie miteinander verknüpfen. Es wird angenommen, dass über die dorsale Bahn phonologische Information – also Information über die wahrgenommenen Sprachlaute und ihre Reihenfolge – und über die ventrale Bahn lexikalisch-semantische Information – also Information über die wahrgenommenen Wörter, ihre Reihenfolge und Bedeutung – vermittelt wird [15]. Wie im vorigen Abschnitt dargelegt, sollten wir uns das nicht als Datenübertragung vorstellen, sondern in dem Sinne, dass über die Fasern Aufmerksamkeit (Verarbeitungskapazität) auf diese Informationen gerichtet wird, so dass sie hinreichend wahrgenommen und lange genug im Kurzzeitgedächtnis „aktiv gehalten“ werden,
Wie im Abschnitt 5.2 bereits erwähnt, wurden .im ECFS, also in der ventralen Bahn, bei stotternden Vorschulkindern strukturelle Defizite entdeckt. In der nachfolgenden, 2017 cweöffentlichten Studie, ebenfalls von Soo-Eun Chang und Kollegen von der Universität von Michigan, wurden jedoch keine signifikanten Gruppenunterschiede in der ventralen Bahn festgestellt. Auch bei älteren stotternden Kindern und bei stotternden Erwachsenen wurden in der ventralen Bahn keine Defizite gefunden. Funktionell könnten Defizite in der ventralen Bahn mit Schwiegikeiten bei der Einbindung der lexikalisch-semantischen Komponente der auditiven Rückmeldung in die Satzplanung zusammenhängen (siehe Abschnitte 2.2 und 3.2 über den Beginn des kindlichen Stotterns). Man muss hier aber weitere Befunde abwarten. Im folgenden geht es deshalb nur um die dorsale Bahn, also um den SLF.
Im Abschnitt 5.1. war ich zu der These gelangt, dass die Fasern des SLF eine Rolle bei der auditiven Rückmeldung spielen und dass ihre verminderte Reifung wahrscheinlich die Folge einer verminderten Aktivierung ist. Die Fasern sind vermindert aktiv, weil Stotterer die auditive Rückmeldung weniger in die Sprechsteuerung einbeziehen. In Analogie zu Muskeln könnte man vereinfacht sagen: Die Fasern sind schwach entwickelt, weil sie wenig trainiert sind.
Bei genauerer Betrachtung gibt es hier allerdings ein Problem: Im Abschnitt 2.1. hatte ich angenommen, dass Stottern durch temporäre Störungen oder Unterbrechungen der auditiven Rückmeldung in den hinteren Bereichen von Sprecheinheiten ausgelöst wird. Ich konnte nicht annehmen, dass die auditive Rückmeldung durchgehend gestört ist, weil unter dieser Bedingung das Monitoring unmöglich wäre – es könnten dann auch keine Fehlermeldungen auftreten – weder aufgrund tatsächlich passierter Fehler noch jene falschen Fehlermeldungen, die meiner Ansicht nach das Stottern auslösen. Wir würden dann also weder unsere Versprecher bemerken, noch könnte es zum Stottern kommen. Deshalb meine Annahme von nur kurzzeitigen Unterbrechungen der auditiven Rückmeldung an den Enden von Sprecheinheiten, durch die das Monitoring kaum beeinträchtigt wäre.
Allerdings gibt es dabei ein Problem: Die Annahme nur kurzzeitiger Unterbrechungen der auditiven Rückmeldung ist nicht gut vereinbar mit der verminderten Myelinisierung im SLF, denn kurze Unterbrechungen der Aktivität hätten auf den Grad der Myelinisierung wahrscheinlich keinen Einfluss. Die Defizite in der Myelinisierung scheinen eher darauf hinzudeuten, dass die betreffenden Fasern permanent minderaktiviert sind. Auch die in PET- und fMRT-Studien gefundenen Minderaktivierungen der sekundären auditiven Areale, besonders des linken STG bei Stotterern (siehe Einführung) sprechen (wegen der Trägheit dieser bildgebenden Verfahren) eher gegen kurzzeitige Unterbrechungen der Aktivität.
Das im vorigen Abschnitt geschilderte Modell der funktionalen Differenzierung zwischen einer dorsalen und einer ventralen Faserbahn erlaubt es nun, dieses Problem zu lösen. Es ist nämlich denkbar, dass über die dorsale Faserbahn beim Sprechen nur derjenige Teil der auditiven Rückmeldung läuft, der bei Stotterern vermutlich gestört ist. Dagegen könnte der andere, nicht gestörte Teil der auditiven Rückmeldung über die ventrale Faserbahn laufen – jener Teil nämlich, der für die inkrementelle Satzplanung, für die Bildung der Erwartungen und für das Erkennen von Versprechern erforderlich ist. Es müsste also gezeigt werden, dass durch eine permanente Unterbrechung des über die dorsale Faserbahn laufenden Teiles der auditiven Rückmeldung außer Stottern keine weitere Beeinträchtigung des Sprechens zu erwarten ist. Das will ich im Folgenden versuchen.
Die dorsale Faserbahn verbindet posterior-temporale und inferior-parietale Regionen mit den Arealen der Sprechsteuerung auf dem Frontalkortex [1] und ist Teil des Fasciculus longitudinalis superior (SLF) (mehr...) . Wie bereits im vorigen Abschnitt erwähnt, wird in aktuellen neurolinguistischen Modellen angenommen, dass über diese Verbindung phonologische Informationen – also Informationen über die wahrgenommenen Sprachlaute und deren Reihenfolge – verarbeitet und beim Sprechen in die Planung und Steuerung einbezogen werden [2] (mehr...) .
Die dorsale Bahn ist zunächst einmal von Bedeutung für das Nachahmen der Sprachlaute und Silben (in der Lallphase) und für das Nachsprechen unbekannter Lautfolgen (neu zu lernende Wörter, Pseudowörter), denn dabei sind die gehörten Laute und deren Reihenfolge die Vorlage für die eigenen Sprechbewegungen. Die dorsale Faserbahn ist daher entscheidend sowohl für den Erwerb der Muttersprache als auch für das Erlernen von Fremdsprachen. Beim alltäglichen routinierten Sprechen spielt diese Funktion der dorsalen Bahn jedoch kaum eine Rolle. Außerdem erfolgt über die dorsale Faserbahn während des Sprechens das phonologische Monitoring, also der Vergleich der produzierten und wahrgenommenen Lautfolge mit der erwarteten Lautfolge (siehe die Abschnitte 1.3. und 1.4.), Das semantische Monitoring hingegen, also der Vergleich des produzierten Inhalts mit der beabsichtigten Botschaft, läuft über die ventrale Faserbahn. Abbildung 17 veranschaulicht die Rolle der dorsalen Faserbahn beim Nachsprechen einer ungeläufigen Lautfolge – also eines neuen Wortes oder eines Pseudowortes – einschließlich des dazugehörigen Monitorings, in zwei Phasen:
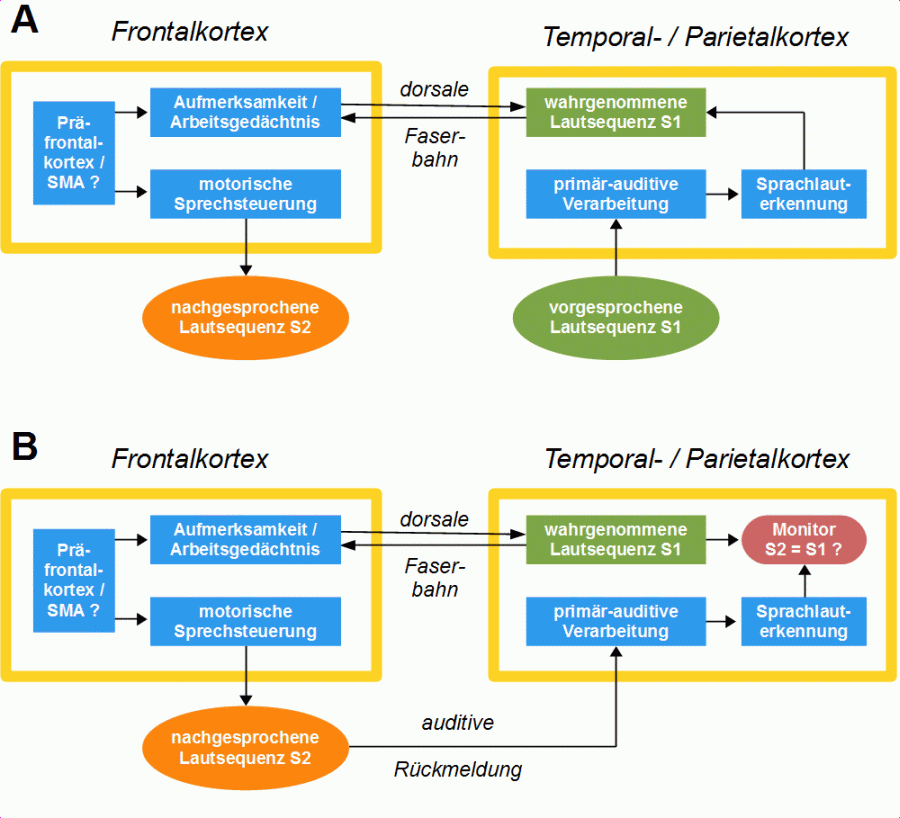
Abbildung 17: Funktion der dorsalen Bahn beim Nachsprechen einer unvertrauten Lautsequenz, z.B. eines Pseudowortes. A = Hören und Nachsprechen, B = Nachsprechen und Monitoring.
Die Funktion der dorsalen Bahn beim Nachsprechen ungeläufiger Lautfolgen besteht zum einen darin, die Aufmerksamkeit auf die Wahrnehmung der „Vorlage“ zu lenken, um auf der Basis dieser Wahrnehmung die Laute oder Silben in,der korrekten Reihenfolge aneinander zu reihen, zum anderen darin, die Vorlage im Arbeitsgedächtnis aktiv zu halten (siehe Abschnitt 5.3.). Beim Nachsprechen einer unvertrauter Lautfolge werden die Laute, Lautverbindungen oder Silben in der wahrgenommenen Reihenfolge auf der Basis vorhandener sprechmotorischer Programme gebildet (siehe Abschnitt 1.2). Dieses Verhalten ist in der frühen Phase des Spracherwerbs erlernt und hochgradig automatisiert, funktioniert jedoch nicht ohne Aufmerksamkeit und nicht ohne dass die akustische Vorlage im Arbeitsgedächtnis aktiv gehalten wird. Das phonologische Monitoring – also die Kontrolle, ob die Lautsequenz korrekt nachgesprochen wurde – erfolgt durch den Vergleich der auditiven Rückmeldung der produzierten Sequenz mit der im Gedächtnis aktiv gehaltenen akustischen Vorlage.
Wie bereits im Abschnitt 1.3. dargelegt, geht es beim phonologischen Monitoring aber nicht nur darum zu prüfen, ob ein Wort korrekt artikuliert wurde. Die Korrektheit eines gesprochenen Wortes schließt logisch auch seine Vollständigkeit ein. Das phonologische Monitoring dürfte daher eine Rolle spielen, wenn ein Kind lernt, ein Wort vollständig bis zum Ende zu sprechen, bevor es das nächste Wort startet. Anders gesagt: Das phonologische Monitoring ist der Kontrollmechanismus für die Sequenzierung, für das korrekte Aneinanderreihen der sprechmotorischen Programme – und dies wiederum ist die Grundlage des flüssigen Sprechens.
Dagegen spielt das phonologische Monitoring beim Erkennen von Versprechern eine eher geringe Rolle, da die meisten Versprecher Verwechslungen ähnlich klingender Wörter sind. Diese Versprecher sind semantisch bedeutsam und können deshalb über die ventrale Faserbahn erkannt werden. Rein phonologische, also nicht-semantische Sprechfehler sind entweder reine Artikulationsfehler oder grammatische Fehler – in beiden Fällen sind nur einzelne Laute oder Endungen falsch, ohne dass ein anderes Wort oder ein anderer Sinn entsteht. Doch ein Sprecher, der seine Sprache beherrscht, wird solche Fehler kaum machen, denn dazu müssen sprechmotorische Programme, also das weitgehend unbewusste Routineverhalten gestört werden – im Gegensatz zu Verwechslungen ähnlich klingender Wörter, die durch Zerstreutheit bei einem bewussten Vorgang, nämlich der Wortwahl entstehen (meist sind die inhaltstragenden Wö,rter einer Äußerung betroffen).
Die dorsale Faserbahn spielt also allenfalls für das Erkennen rein phonologischer, semantisch irrelevanter Versprecher eine Rolle, und die kommen bei jemandem, der seine Muttersprache spricht und sie beherrscht, kaum vor. Fiele die dorsale Bahn aus, so würde sich dies auf die Erkennung von Versprechern daher kaum auswirken.
Welche Rolle hat nun die dorsale Bahn beim routinierten Sprechen? Sie sorgt dafür dass, genug Aufmerksamkeit auf die auditive Rückmeldung gerichtet ist und dass die wahrgenommenen Lautsequenzen so lange im Gedächtnis aktiv gehalten werden, bis die Wörter erkannt und die korrekten Erwartungen gebildet sind. sodass Wahrnehmung und Erwartung verglichen werden können (Abbildung 18). Die Worterkennung kann unterschiedlich lange dauern, je nach dem, wie viele Laute des Wortes erkannt werden müssen, damit es im gegebenen Kontext identifizierbar ist. Aus diesem Grund müssen die über die auditive Rückmeldung wahrgenommenen Sequenzen lange genug im Arbeitsgedächtnis aktiv gehalten werden.
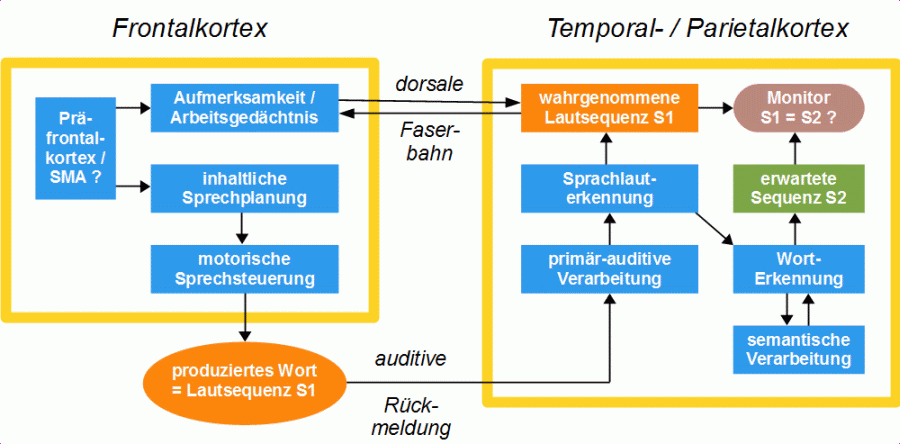
Abbildung 18: Funktion der dorsalen Bahn beim normalen Sprechen (Artikulation und äußeres Hören sind weggelassen, ebenso die ventrale Bahn, die von der semantischen Verarbeitung zum Frontalkortex läuft)
Die Funktion der dorsalen Faserbahn beim normalen, routinierten Sprechen dürfte also nur darin bestehen, die Aufmerksamkeit in hinreichendem Maße auf die auditive Rückmeldung zu richten, sodass die selbst produzierten Lautfolgen vollständig wahrgenommen und lange genug im Kurzzeitgedächtnis aktiv gehalten werden.
Was geschieht nun, wenn zu viel Aufmerksamkeit von der auditiven Rückmeldung abgezogen wird? Da das Arbeitsgedächtnis von der Aufmerksamkeit abhängig ist (siehe Abschnitt 5.3.), wird die produzierte Lautsequenz nicht ausreichend auditiv wahrgenommen und/oder nicht ausreichend im Gedächtnis aktiv gehalten. Das kann dazu führen, dass nur die anfänglichen Laute einer Sequenz erkannt und im Gedächtnis behalten werden. Das Ende des Wortes oder der Phrase würde also beim Monitoring fehlen. Das wiederum könnte zu einer falschen Fehlermeldung führen und eine Unterbrechung des Redeflusses zur Folge haben (siehe Abschnitt 2.1.)..
Andererseits dürften die wenigen Anfangslaute pro Sequenz, die bei verminderter Aufmerksamkeit vermutlich wahrgenommen und/oder im Gedächtnis aktiv gehalten werden, meist ausreichen, um die Wörter und Phrasen im Kontext einer Äußerung zu erkennen (siehe Abschnitt 1.4.). Weder die inkrementelle Satzplanung noch das semantische Monitoring wären also durch das Abziehen der Aufmerksamkeit beeinträchtigt. Das Erkennen der Wörter auf der Basis weniger Anfangslaute ermöglicht auch die Bildung der Erwartungen der korrekten Lautfolgen. Das phonologische Monitoring würde also ebenfalls stattfinden – mit den im vorigen Absatz beschriebenen Konsequenzen. Wir können die oben gestellte Frage also folgendermaßen beantworten;
Die permanente Unterbrechung des phonologischen Teils der auditiven Rückmeldung während des Sprechens kann zu falschen Fehlermeldungen beim Monitoring und dadurch zu Stottern führen. Weitere Beeinträchtigungen des Sprechens wären jedoch nicht zu erwarten.
Eine über Jahre andauernde permanente Minderaktivierung der Fasern während des Sprechens könnte aber nur dann zu einem Defizit in der Myelinisierung führen, wenn diese Fasern bei der Wahrnehmung der Sprache anderer Personen keine große Rolle spielen. Dies kann man jedoch annehmen: Auch beim Verstehen der Rede einer anderen Person werden die Wörter im Satzkontext meist an den vorderen Teilen der Lautsequenz erkannt. Dadurch kann der Zuhörer Erwartungen bilden und Versprecher meist sofort bemerken (siehe Abschnitt 1.4.). Für das Satzverstehen muss der bereits gehörte Teil des Satzes so lange im Gedächtnis aktiv gehalten werden, bis der Sinn des ganzen Satzes verstanden ist. Da es sich hierbei aber um lexikalisch-semantische Information handelt, geschieht das über die ventrale Faserbahn.
Eine stärkere Einbeziehung phonologischer Information und damit der dorsalen Faserbahn in das Verstehen der Rede anderer Personen wird nur in Ausnahmefällen erforderlich sein, z.B. bei unbekannten Wörtern oder unerwarteten, sich nicht aus dem Kontext ergebenden grammatischen Endungen. Ob Stotterer in derartigen Fällen mehr Schwierigkeiten haben als Nichtstotterern, darüber gibt es meines Wissens keine Untersuchungen. Es wurde allerdings in mehreren Studien gezeigt, dass Stotterer Defizite beim Unterscheiden von Phonemen [4] und beim Nachsprechen von Pseudowörtern [5] haben.
Schwierigkeiten bei der Phonem-Unterscheidung könnten mit Defiziten in der auditiven Aufmerksamkeit zusammenhängen. Für diese Annahme spricht, dass in entsprechenden Untersuchungen sich die Leistungen der Versuchspersonen zum Ende der Tests hin, also mit nachlassender Konzentration, verschlechterten [6]. Defizite in der auditiven Aufmerksamkeit bzw. in Hirnprozessen, die die Steuerung der auditiven Aufmerksamkeit beeinflussen, wurden bei Stotterern auch in anderen Studien festgestellt [7]. Die im Vergleich zu Normalsprechern durchschnittlich schlechteren Leistungen von stotternden Kindern und Erwachsenen beim Nachsprechen von Pseudowörtern [5] deuten auf Defizite beim phonologischen Kurzzeitgedächtnis hin.
In einer Studie mit chronisch stotternden Kindern und Remittenten im Vorschulalter wurde zudem gezeigt, dass die Remittenten (als Gruppe) besser als die stotternden Kinder – und sogar etwas besser als Kinder, die nie gestottert hatten – in der Lage waren, Pseudowörter nachzusprechen [8]. In einer anderen Untersuchung wurde beim Vergleich zwischen stotternden Kindern im Alter zwischen 9 und 12 Jahren, gleichaltrigen Remittenten und Kindern, die nie gestottert hatten festgestellt, dass bei den Remittenten (als Gruppe) zwar noch Defizite in der Faserdichte innerhalb des linken SLF bestanden, dass diese Defizite aber geringer als bei den stotternden Kindern waren und/oder auf der rechten Hirnhälfte kompensiert waren [9] (mehr) .
All diese Befunde sind gut vereinbar mit der Annahme, dass die dorsale Faserbahn mit der auditiven Aufmerksamkeit und dem phonologischen Kurzzeitgedächtnis zu tun hat. Noch deutlicher wird dieser Zusammenhang bei Personen mit einer sogenannten Leitungsaphasie. Die Störung äußert sich vor allem darin, dass die Betroffenen große Schwierigkeiten beim Nachsprechen von Pseudowörtern haben – bei ansonsten relativ intaktem Sprachvermögen und Sprachverstehen. Ursache einer Leitungsaphasie ist typischerweise eine Läsion innerhalb der dorsalen Faserbahn durch einen Tumor oder infolge einer Hirnverletzung [13].
Die Anatomie des SLF scheint noch nicht völlig aufgeklärt zu sein. Laut Makris et al. (2005) lassen sich vier Teilstränge unterscheiden, von denen zumindest zwei – der SLF III und der Fasciculus arcuatus – mit der Sprachverarbeitung und der Steuerung des Sprechens zu tun haben, Laut Catani et al. (2005) lässt sich der Fasciculus arcuatus in zwei Teilstränge – eine direkte und eine indirekte Verbindung – untergliedern, wobei letztere über den inferioren Parietalkortex verläuft. Die bei chronischen Stotterern gefundenen Defizite im linken SLF werden manchmal dem SLF III und manchmal dem Fasciculus arcuatus zugeordnet [14].
Für unsere Thema spielen diese Unklarheiten jedoch keine Rolle: Als „dorsale Faserbahn“ bezeichne ich hier einfach diejenigen Teile des SLF, die mit Sprachverarbeitung und Sprechsteuerung zu tun haben. Laut Makris et al. (2005) haben der SLF II und III und der Fasciculus arcuatus Endigungen im BA 46, einem Kortexareal, das für Gedächtnisfunktionen verantwortlich zu sein scheint.
(zurück)
Funktionell lassen sich innerhalb der dorsalen Faserbahn zwei Bereiche unterscheiden: Einerseits werden über die dorsale Bahn auditive und propriozeptiv-taktile Rückmeldungs-Informationen in die Steuerung der Artikulation einbezogen, z.B. in die Steuerung der Phonationsintensität (Lautstärke), der Phonationsdauer (Vokallänge) und der Deutlickeit (Akkuratheit der Mundbewegungen). Diese sensomotorischen Bahnen scheinen weitgehend angeboren zu sein. Ich gehe darauf nicht weiter ein, da ich nicht annehme, dass bei Stotterern hier wesentliche Defizite bestehen, denn in den Phasen flüssigen Sprechens ist die Artikulation von Stotterern in der Regel normal.
Der zweite Funktionsbereich der dorsalen Faserbahn ist die Einbeziehung phonologischer Information in die Planung und Steuerung des Sprechens. Teile des SLF verbinden den posterioren superioren temporalen Gyrus und Sulcus (pSTG, pSTS) sowie den inferioren Parietalkortex mit den Brodmann-Arealen 44 und 46. Es wird allgemein angenommen, dass im pSTG und pSTS die phonologische Verarbeitung, also das Erkennen der Sprachlaute und Lautsequenzen lokalisiert ist [10]. Der Verarbeitungsprozess vom Erkennen der Sprachlaute zum Erkennen der Wörter und ihrer Bedeutungen verläuft auf dem oberen und mittleren Temporalkortex von posterior nach anterior [11].
(zurück)
Die Remission des Stotterns scheint also daran gebunden zu sein, dass ein strukturelles Defizit in der linken dorsalen Faserbahn entweder nicht zu groß ist oder auf der rechten Hemisphäre kompensiert wird. Zugleich sind Kinder, die vom Stottern remittiert sind (= geringeres und/oder kompensiertes Defizit in der dorsalen Bahn) besser in der Lage, Pseudowörter zu wiederholen. Bei diesen Kindern funktionieren auditive Aufmerksamkeit und/oder phonologisches Kurzzeitgedächtnis also besser als bei Kindern, deren Stottern chronisch geworden ist. Die Remission scheint demnach gebunden zu sein an eine bessere auditive Aufmerksamkeit und/oder ein besseres auditives Kurzzeitgedächtnis.
Das lässt sich möglicherweise für die Therapie nutzen: Wenn meine Annahme richtig ist, dass es sich (1) bei den strukturellen Defiziten in der dorsalen Faserbahn um eine verzögerte Myelinisierung infolge einer andauernden Minderaktivierung handelt (siehe Abschnitt 5.1.), dass (2) die Myelinisierung durch häufige Aktivierung, also durch Training verbessert werden kann, und dass (3) die Fasern beim Nachsprechen aktiviert werden, dann sollte ein Training im Nachsprechen die Myelinisierung der Fasern verbessern und zur Überwindung des Stotterns beitragen können.
Dies wurde in mehreren Studien in den 60er und 70er Jahren auch tatsächlich gezeigt [12]. Dabei wurde die Methode des „Schattensprechens“ (Shadowing) vor allem bei stotternden Kindern mit überwiegend guten Resultaten angewandt – ohne dass man damals die Ursachen für die Wirksamkeit der Methode erkannt hat. Siehe dazu die ausführliche Beschreibungen der Studien im BVSS-Forum).
Beim Schattensprechen wird ein Text gleichzeitig gehört und (mit geringer Verzögerung) nachgesprochen. Es ist dem Nachsprechen von Pseudowörtern insofern nicht unähnlich, als das semantische Verstehen der nachzusprechenden Sätze nicht erforderlich ist und aus Zeitgründen auch nur begrenzt stattfindet. Deshalb kann man annehmen, dass die dorsale Bahn dabei stark einbezogen ist, z.B. beim Nachsprechen der Flexionsformen. Vielleicht wäre aber ein Training im Pseudowort-Nachsprechen noch effektiver, weil dadurch die dorsale Faserbahn gezielter trainiert werden würde.
(zurück)