 StotterTheorie
StotterTheorie
StotterTheorie
StotterTheorie
In Abbildung 4 sind die Abbildungen 2 und 3 zu einem Modell der Sprachproduktion zusammengefasst. Es handelt sich um eine Synthese aus Levelts Modell der zwei Rückmeldeschleifen (siehe Abb.)und dem Modell mentalen Lexikons (mit akustischen Wortformen und sprechmotorischen Programmen) von Engelkamp und Rummer (siehe Abschnitt 1.2). Nicht alle in der Grafik dargestellten Funktionen können gleichzeitig aktiv sein; das gilt sowohl für die äußere / innere Hör-Rückmeldung als auch für selbst formuliertes Sprechen / Nachsprechen (mehr...).
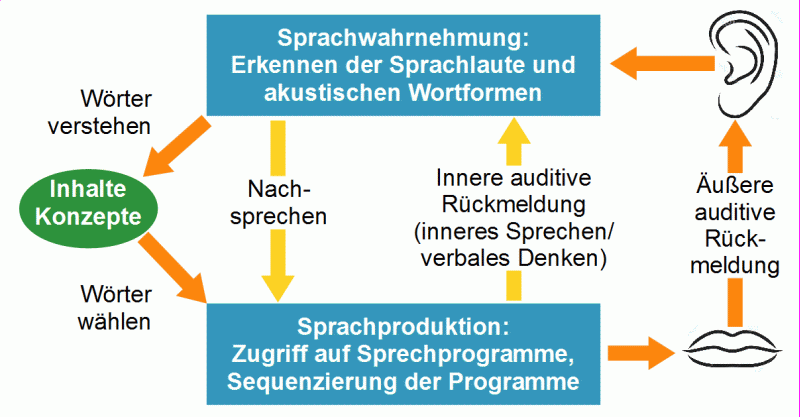
Abbildung 4: Modell der Sprachproduktion. Nicht alle Funktionen sind gleichzeitig aktiv. Orange Pfeile = Funktionen während des normalen spontanen Sprechens.
Konzepte (Wortinhalte) sind in diesem Modell keine dritte Art sprachlicher Repräsentationen im Gehirn neben den akustischen Wortformen und den motorischen Sprechprogrammen. Vielmehr sind Konzepte Verknüpfungen der Wortformen untereinander sowie der Wortformen zu nichtsprachlichen Repräsentationen (siehe dazu die Fußnote im Abschnitt 1.2.)
In Abbildung 4 verbindet ein Pfeil mit der Bezeichnung „innere auditive Rückmeldung“ die Sprachproduktion mit dem Sprachverstehen. Diese Verbindung im Gehirn ermöglicht es uns, beim stillen Lesen und beim Denken innerlich Sprache zu produzieren und sie wahrzunehmen und zu verstehen (so verstehen wir unsere eigenen Gedanken). Außerdam ermöglicht uns die innere Hör-Rückmeldung auch, ohne Probleme (laut) zu sprechen, wenn wir uns äußerlich nicht hören können – wegen starken Lärms oder infolge eines Hörverlustes.
Die Existenz der inneren Hör-Rückmeldung und die erstaunliche Tatsache, dass dann, wenn sie aktiv ist – beim stillen Lesen und beim sprachlichen Denken – kein (inneres) Stottern auftritt, wurden in der Forschung weitgehend ignoriert. Doch beides hat miteinander zu tun, und wenn wir diesen Zusammenhang verstehen, verstehen wir auch die Natur des Stotterns besser.
Das innere Sprechen, die „Stimme im Kopf“, die wir beim Denken oder stillen Lesen hören, wurde im Kontext von Lese-/Rechtschreibschwäche, Arbeitsgedächtnis und Schizophrenie intensiv untersucht [1]. Es wurden zwei Aspekte oder Komponenten des inneren Sprechens unterschieden: ein Produktionsaspekt, manchmal als „innere Artikulation“ oder „Subvokalisierung“ bezeichnet, und ein Wahrnehmungsaspekt, der etwa als „inneres Hören“ oder „auditive verbale Vorstellung“ bezeichnet wird [2]. Oder es wird einfach zwischen „innerer Stimme“ und „innerem Ohr“ unterschieden [3].
Inneres Sprechen ist nicht objektiv beobachtbar. Es wurde aber indirekt untersucht, z.B. indem man Versuchspersonen laut, aber mit vollständiger künstlicher Vertäubung mit weißem Rauschen) sprechen ließ [4]. Die Forscher gingen ganz selbstverständlich davon aus, dass unter künstlicher Vertäubung auch das laute Sprechen über die innere Hör-Rückmeldung kontrolliert wird. Auch wenn wir „stumm sprechen“, also artikulieren ohne Phonation bei angehaltenem Atem, sodass nichts, auch kein Flüstern, zu hören ist, wird das Sprechen über die innere Hör-Rückmeldung kontrolliert („artikuliertes inneres Sprechen“ [5]).
Dass beim innere Sprechen tatsächlich Sprachproduktion stattfindet, zeigen die vielen Ähnlichkeiten zwischen äußerem und innerem Sprechen. Das innere Sprechen hat nahezu den gleichen artikulatorischen Reichtum wie das laute Sprechen, einschließlich Silbenstruktur, Betonung und Prosodie (Satzmelodie) [6]. Man kann innerlich langsam oder schnell sprechen [7], man kann seine Stimme verändern [8] und sogar willentlich (pseudo-)stottern [9].
Auch die Eigenschaften und das Erkennung eigener Sprechfehler beim äußerem und innerem Sprechen wurde untersucht. Die Ergebnisse deuten darauf hin, dass „Planungsprozesse unter Bedingungen, die eine tatsächliche Ausführung durch die Sprachmotorik erfordern, in hohem Maße vergleichbar sind mit denen, bei denen dies nicht der Fall ist“ [10], und dass „unsere ‚innere Stimme‘ sehr wie unsere äußere Sprache klingt und auf die gleiche Weise erzeugt wird, ob offen artikuliert oder nicht“ [11].
Die Sprechmotorik ist sowohl an der äußeren als auch beim innere Sprechen beteiligt. Das innere Sprechen beruht auf motorischer Simulation; es wird durch Sequenzen motorischer Befehle (also sprechmotorische Programme) gesteuert; diese lösen im Wahrnehmungssystem die entsprechenden Höreindrücke aus (motorisch-sensorische Transformation) [12]. Motorische und prä-motorische Regionen im Gehirn sind auch beim inneren Sprechen aktiv [13]. Meist ist inneres Sprechen von fast unmerklichen Bewegungen der Lippen, der Zunge und der Kehlkopfmuskulatur begleitet [14]. Sogar die Atmung wechselt beim inneren Sprechen, trotz fehlender Phonation, vom Grundmodus in den Sprachmodus [15].
Das innere Sprechen entwickelt sich in der Kindheit. Zuvor muss das Kind lernen, korrekte Sätze zu bilden, die Voraussetzung für klares Denken, Das geschieht im Gespräch mit anderen. Dann findet ein allmählicher Übergang vom lauten Selbstgespräch über das Flüstern zu lautloser Artikulation und schließlich zum inneren Sprechen / Denken statt [16]. Mit etwa fünf oder sechs Jahren (dem Erreichen der Schulreife) ist dieser Prozess abgeschlossen [17]. Vierjährige haben normalerweise noch kein Bewusstsein von innerem Sprechen / Denken [18].
Das bedeutet, dass das innere Sprechen, also das Denken, nicht die Grundlage der lauten Sprechens ist. Umgekehrt bildet das äußere Sprechen, das zuerst gelernt werden muss, die Basis für das sprachliche Denken (also das Denken im engeren Sinne). Und, wie schon am Schluss des vorigen Abschnitts dargelegt: Dem spontanen Sprechen geht kein Denken des zu sprechenden Satzes voraus; es ist vielmehr ein unmittelbares Laut-Machen der Gedanken.
Beim stillen Lesen und Denken findet (wegen des zu geringen Ausatemdruckes) keine Phonation statt, und die meisten Artikulationsbewegungen sind gehemmt. Doch die sprechmotorischen Programme laufen im Gehirn genauso ab wie beim äußeren Sprechen. Angesichts dessen ist es nicht selbstverständlich, sondern erstaunlich, dass Stotterer beim stillen Lesen und Denken keine Probleme haben. Eine Erklärung dieses Phänomens wird uns helfen, die Natur des Stotterns zu verstehen.
Beispiel für ein reines Nachsprechen, bei dem kein semantisches Verstehen stattfindet, ist das Nachsprechen von Pseudo- oder Nonsens-Wörtern, also von Lautfolgen ohne Bedeutung. Weil für das Sprechen von erstmals gehörten Pseudowörtern keine Wort-Sprechprogramme zur Verfügung stehen, muss das motorischen Programm für das Sprechen des Pseudowortes aus Sprechprogrammen für Einzellaute, Lautverbindungen oder geläufige Silben zusammengesetzt werden (phonologische Kodierung).
Das Nachsprechen eines Pseudowortes wird um so leichter sein, je geläufiger dem Sprecher die Silben und Lautverbindungen sind, aus denen es besteht – je mehr er also auf komplexere Sprechprogramme, z.B für ganze Silben, zugreifen kann und je weniger aus Einzellauten zusammengesetzt werden muss.
Am Beispiel des Pseudowort-Nachsprechens wird deutlich, dass die phonologische Kodierung im vorgeschlagenen Modell durchaus enthalten ist – aber eher als Sonderfall. Phonologische Kodierung bedeutet, dass ein Wort, für das noch kein Sprechprogramm vorhanden ist, aus den motorischen Programmen der Einzellaute oder Lautverbindungen zusammengefügt werden muss. Diese Fähigkeit ermöglicht es uns auch, neue Wörter sprechen zu lernen, z.B. beim Erlernen einer Fremdsprachen
Mit ein wenig Übung ist es möglich, ein Pseudowort. z.B. „matula“, sprechen zu lernen und es sich einzuprägen, sodass man es beim Hören wiedererkennt und es wie ein gewöhnliches Wort bei Bedarf sofort sprechen kann. Das zeigt, dass die akustischen Wortformen und die motorischen Sprechprogramme prinzipiell unabhängig von Inhalten existieren können.
Anders als Levelt [1] müssen wir daher im Gehirn kein spezielles „Silben-Verzeichnis“ (für Silben ohne Wortbedeutung) annehmen. Es gibt in meinem Modell keinen Wesensunterschied zwischen Sprechprogrammen für einzelne Laute, Silben, Wörter, geläufige Phrasen oder ein auswendig gelerntes Gedicht. Zwar sind diese Programme unterschiedlich komplex, doch eie sind allesamt durch Übung, durch Wiederholung erworbene motorische Routinen, auf die bei Bedarf zugegriffen werden kann.
(zurück)