StotterTheorie
StotterTheorie
StotterTheorie
StotterTheorie
Wenn eine Bewegung aus mehreren Teilbewegungen besteht, die in einer bestimmten Reihenfolge ausgeführt werden, spricht man von einer Bewegungssequenz. Auch das Sprechen ist eine (sehr komplexe) Bewegungssequenz: Laute werden zu Silben, Silben zu Wörtern, Wörter zu Sätzen aneinandergereiht.
Während aber in einfachen Bewegungsfolgen, z.B. beim Binden einer Schleife, die Reihenfolge der Teilbewegungen festgelegt ist, ist das beim Sprechen nicht generell der Fall: Wohl ist die Reihenfolge der Laute in einem Wort immer dieselbe, und für die Reihenfolge der Wörter in einem Satz gibt es Regeln, doch diese lassen Freiraum für Variabilität. Während das Resultat der Sequenz „Schleife-Binden“ nach erfolgreichem Abschluss immer eine Schleife ist, kann das Resultat einer Sprechsequenz ein nie zuvor ausgesprochener Satz sein.
Wie werden Bewegungssequenzen vom Gehirn gesteuert, sodass sie flüssig ausgeführt werden können? In der ersten Hälfte des 20. Jahrhunderts glaubte man, sie würden über die sensorische Rückmeldung gesteuert. Man nahm also an, der Start der nächsten Teilbewegung einer Sequenz sei eine Reaktion auf die sinnliche Wahrnehmung der vorausgegangenen Teilbewegung und das, was sie gegebenenfalls bewirkt hat.
Dagegen spricht jedoch, dass die Reaktion auf eine Sinneswahrnehmung eine gewisse Zeit benötigt. Vom Reiz bis zur Reaktion vergehen 150 Millisekunden oder mehr. Wegen dieser Reaktionszeit könnte eine allein über die Rückmeldung gesteuerte Bewegungssequenz niemals flüssig ausgeführt werden. Gegen eine rein rückmeldungsbasierte Steuerung spricht außerdem, dass Bewegungssequenzen, nachdem sie einmal erlernt sind, oft auch dann ausgeführt werden können, wenn die sensorische Rückmeldung unterbrochen ist. Das gilt auch für das Sprechen.
Deshalb nahm Karl Lashley an, dass Bewegungssequenzen durch Pläne oder Programme „vorwärtsgesteuert“ werden – im Fall komplexer Sequenzen durch ein hierarchisches System solcher Programme [1]. Lashleys Ansicht kann heute als bestätigt gelten [2].
Was allerdings das Sprechen betrifft, so hat Bernhard Lee 1951 entdeckt, dass der Sprachfluss gesunder Personen durch die Verzögerung der Hör-Rückmeldung gestört werden kann [3]
(mehr...). Später haben Theodor Kalveram und Lutz Jäncke gezeigt, dass bereits eine Rückmeldungs-Verzögerung von 40 Millisekunden (unterhalb der Schwelle der bewussten Wahrnehmung) die Phonationsdauer langer (betonter) Silben verlängert [4]. Das zeigt, dass das Sprechen nicht rein vorwärts-gesteuert ist – die Hör-Rückmeldung spielt eine Rolle.
Betrachten wir kurz, wie eine Bewegungssequenz erlernt wird und nehmen wir als einfaches Beispiel wieder das Schleife-Binden: Man lernt zunächst, die Teilbewegungen Schritt für Schritt nacheinander auszuführen. In der Anfangsphase ist es hilfreich, zu kontrollieren, ob eine Teilbewegung erfolgreich beendet ist, bevor die nächste begonnen wird. Falls ein Fehler passiert ist, kann man ihn dann sofort korrigieren und muss nicht wieder ganz von vorn anfangen. Diese begleitende Kontrolle bezeichne ich als Monitoring.
Während die Teilbewegungen einer Sequenz und deren Reihenfolge vorwärts- oder programmgesteuert sind, stellt das Monitoring ein Element von rückmeldungsbasierter Steuerung dar. In der Lernphase wird das Monitoring bewusst durchgeführt, oft mit der Folge, dass die Sequenz noch nicht ganz flüssig ausgeführt werden kann.
Wird die Sequenz dann sicher beherrscht, läuft das Monitoring automatisch nebenher: Beim Schnüren der Schuhe kontrolliert man nicht mehr bewusst, ob jede Teilbewegung korrekt war – doch wenn etwas schiefgegangen ist, spürt man es und bricht die Sequenz ab, um den misslungenen Teilschritt zu wiederholen.
Beide Formen der Steuerung sind in Abbildung 1 veranschaulicht. Oben eine Sequenz am Beginn der Lernphase. Die Steuerung erfolgt über die Rückmeldung; der Erfolg jeder Teilbewegung wird bewusst wahrgenommen (Pfeil zum Monitor), und erst danach wird als Reaktion darauf die nächste Teilbewegung gestartet (Pfeil vom Monitor). Nach einem Fehler wird die betreffende Teilbewegung wiederholt.
In Abbildung 1 unten eine bereits automatisierte Sequenz: Der Monitor kontrolliert laufend, ob die Teilbewegungen erfolgreich beendet wurden, doch der Start der nächsten Bewegung erfolgt davon unabhängig durch das Programm (horizontaler Pfeil, der zugleich die Zeitachse symbolisiert). Stellt der Monitor einen Fehler fest, bricht er nach einer Reaktionszeit die Sequenz ab. Danach wird die fehlerhafte Teilbewegung wiederholt.
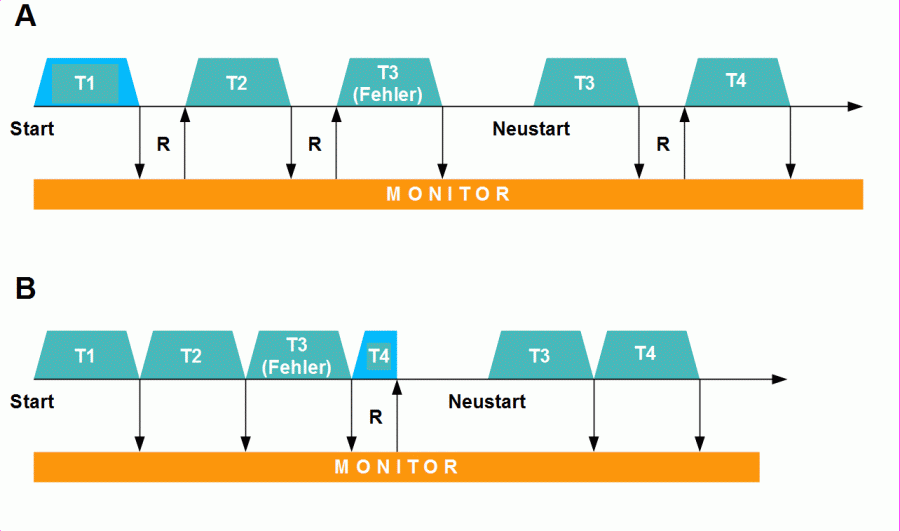
Abbildung 1: Rückmeldungsbasierte Steuerung (A) und Vorwärtssteuerung mit parallel laufendem Monitoring (B). T = Teilbewegung, R = Reaktionszeit.
Das automatische, meist unbewusste Monitoring ist also ein begleitendes rückmeldungsbasiertes Steuerungselement für Bewegungssequenzen. Es stellt sicher, dass die nächste Teilbewegung nur dann ausgeführt wird, wenn die aktuelle erfolgreich beendet wurde. Nachdem die Sequenz erlernt ist, greift der Monitor nur noch ein, wenn er einen Fehler feststellt. Er unterbricht dann den Bewegungsfluss – allerdings erst nach einer Reaktionszeit. Das bedeutet, dass die nächste Teilbewegung oft noch gestartet werden kann, dann aber abgebrochen wird.
Willem Levelt's „Perceptual Loop Theory“ (mehr...) und seine „Main Interruption Rule“ [5], die im übernächsten Abschnitt näher betrachtet werden, können als Spezialfall einer solchen begleitenden rückmeldungsbasierten Steuerung im Bereich der Sprachproduktion angesehen werden: Eine meist automatisch und unbewusst arbeitende Kontrollinstanz im Gehirn überprüft laufend die Hör-Rückmeldung und unterbricht den Sprachfluss, wenn ein Fehler registriert wird.
Wenn jemand in ein Mikrofon spricht und sein Sprechen über Kopfhörer hört, kann diese Hör-Rückmeldung künstlich verzögert werden. In der englischsprachigen Fachliteratur wird das als delayed auditory feedback bezeichnet, abgekürzt DAF. Bei einer Verzögerung von ungefähr Silbenlänge (1/4–1/5 Sekunde) treten Wiederholungen und Dehnungen von Lauten und Silben auf. Diese Wirkung wird heute „Lee-Effekt“ genannt; Lee selbst bezeichnete sie als „künstliches Stottern“ (artificial stutter). Die Symptome unterscheiden sich aber deutlich von echtem Stottern; es fehlen Muskelanspannungen, und Wiederholungen treten eher an den Endsilben der Wörter auf und nicht, wie beim Stottern, am Beginn.
(zurück)
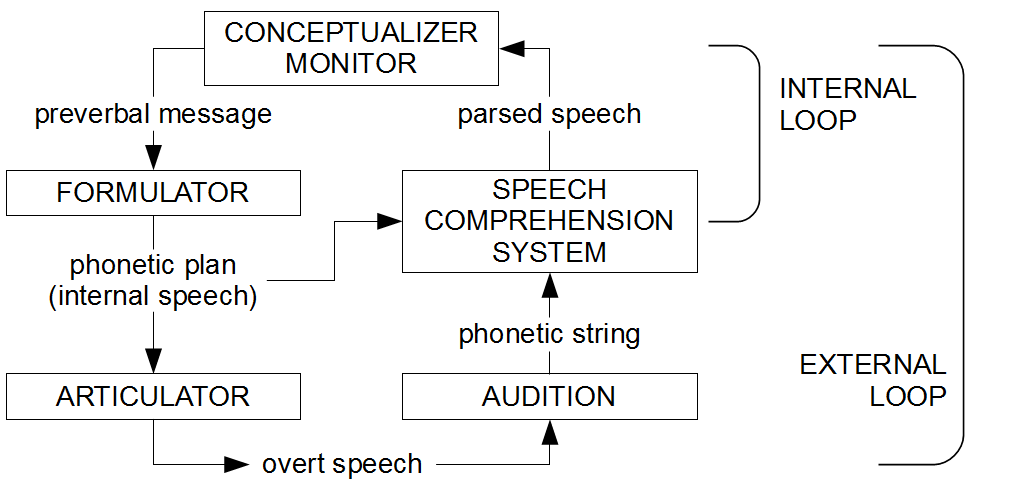
Es ist wohl das zur Zeit bekannteste und gebräuchlichste Modell der Sprachverarbeitung. Da ich im weiteren Text darauf Bezug nehmen werde, stelle ich es hier kurz vor. Die Abbildung zeigt eine vereinfachte, auf die Sprachproduktion und die Rückmeldeschleifen beschränkte Variante und entspricht Fig. 12.3 auf Seite 470 in Levelts Buch „Speaking“ [5].