Im Abschnitt 2. 1. hatte ich angenommen, dass Stottern innerhalb gebundener Sprache durch eine Störung oder Unterbrechung der auditiven Rückmeldung im hinteren Bereich derjenigen Sprecheinheit verursacht wird, die dem Stotterereignis vorausgeht. Es sind nun zwei Fragen zu beantworten: Von welcher Art sind die Störungen der auditiven Rückmeldung, und wodurch werden sie verursacht?
Im Jahr 1953 ließ der Physiker Colin Cherry in einem Experiment (einem sogenannten dichotischen Hörtest) die Versuchsteilnehmer zwei unterschiedliche verbale „Botschaften“ über Kopfhörer hören, jede in einem Ohr. Die Teilnehmer wurden angewiesen, nur auf eine der beiden Botschaften zu achten und sie zu wiederholen. Als sie anschließend gebeten wurden, den Inhalt der ignorierten Botschaft wiederzugeben, waren die Versuchspersonen nicht nur außerstande, die Worte der ignorierten Botschaft zu wiederholen – sie schienen nicht einmal einen Wechsel der Sprache vom Englischen ins Deutsche und zu rückwärts laufender Sprache bemerkt zu haben. Nur wenn der unbeachtete Sprecher das Geschlecht gewechselt hatte, wenn also die Stimme sich deutlich verändert hatte, hatten die Teilnehmer es bemerkt [1].
Diese Beobachtung,ist als „Cocktailparty-Effekt“ bekannt geworden. Der Cocktailparty-Effekt ist Ausdruck eines Mechanismus der selektiven Aufmerksamkeit, der es uns erlaubt, in einem Stimmengewirr einer einzelnen Person zuzuhören und deren Rede zu verstehen. Indem wir die Aufmerksamkeit auf eine einzelne Stimme richten, filtern wir diese Stimme quasi aus dem Stimmengewirr heraus und blenden gleichzeitig alle anderen Stimmen aus – d.h., wir nehmen die anderen Stimmen nur noch als Geräuschkulisse wahr.
Das bedeutet allerdings umgekehrt: Wenn wir die Aufmerksamkeit nicht auf die Stimme eines Sprechers richten, können wir dessen Rede nicht verstehen. Alles, was wir ohne Aufmerksamkeit auf die Stimme verstehen, sind einige wenige Wörter. Dazu gehören der eigene Name [14] und Anrufe wie „Hallo!“, „Achtung!“ oder „Hilfe!“. Solche Wörter sind Signale und haben die Funktion, die Aufmerksamkeit auf die Stimme des Sprechers zu ziehen.
Colin Cherrys Resultate wurden in den letzten Jahren mit Hilfe funktioneller Magnetresonanztomografie (fMRT) bestätigt. In einem Experiment an der Universität Bergen in Norwegen wurden größere Aktivierungen in den sensorischen Spracharealen auf der linken (sprachdominanten) Hirnhälfte gefunden, wenn die Teilnehmer aufmerksam auf sprachliche Reize hörten, Nahmen die Teilnehmer dagegen dieselben Reize nur passiv wahr, ohne Fokussierung der Aufmerksamkeit, dann waren die Aktivierungen geringer und weniger links lateralisiert. Die Aufmerksamkeit ermöglicht offenbar das Sprachverstehen, indem sie die neuronale Aktivität gegenüber Sprachlauten beeinflusst [2].
In einem anderen Experiment, durchgeführt am Sprachlabor von Einar Liebenthal am Medical College of Wisconsin, ließ man Versuchspersonen auf auditive (sprachliche und nichtsprachliche) Reize hören und, als Kontrast, diese auditiven Reize (die weiterhin präsentiert wurden) ignorieren und statt dessen die Aufmerksamkeit auf einen visuellen Reiz richten. Es zeigte sich, dass die Hörareale deutlich mehr aktiviert waren, wenn die Teilnehmer ihre Aufmerksamkeit auf einen auditiven Reiz richteten, und weniger, wenn sie den auditiven Reiz ignorierten. Wurde Sprache als auditiver Stimulus präsentiert, dann waren einige Areale, von denen angenommen wird, dass sie mit dem Sprachverstehen zu tun haben, überhaupt nur dann aktiviert, wenn die Teilnehmer ihre Aufmerksamkeit auf die Sprachreize richteten. Die Autoren der Studie schlussfolgerten, dass die Verarbeitung phonetischer und lexikalisch-semantischer Informationen sehr beschränkt ist, wenn die Aufmerksamkeit nicht auf den auditiven Kanal, also auf das Hören, gerichtet ist [3].
Doch was hat das mit dem Stottern zu tun? Im Abschnitt 1. 4. hatte ich angenommen, dass das Monitoring, die automatische Selbstkontrolle des Sprechens in der Weise funktioniert, dass die Wahrnehmung der eigenen Rede mit Erwartungen der korrekten Lautfolgen von Wörtern und Phrasen sowie mit der beabsichtigten Botschaft verglichen wird. Dafür ist das Hören und Erkennen der selbstproduzierten Laute und Wörter erforderlich. Wir können davon ausgehen, dass ein Sprecher seine eigene Rede, wenn er sie hört, in derselben Weise verarbeitet und versteht wie die Rede einer anderen Person [4]. Demzufolge können wir annehmen, dass die oben berichteten Resultate, obwohl sie nur die Wahrnehmung der Rede anderer Personen betreffen, auch für die Wahrnehmung und das Verstehen der eigenen Rede gelten – dass also ür das Erkennen der Laute und Wörter der eigenen Rede ein hinreichendes Maß an Aufmerksamkeit auf den auditiven Kanal gerichtet werden muss.
Diese Annahme wird unterstützt durch eine 2016 veröffentlichte Studie aus Kanada [15], in der untersucht wurde, ob die Reaktion auf eine Manipulation der Tonhöhe in der auditiven Rückmeldung sich verändert, wenn die Aufmerksamkeit vom Hören auf die eigene Stimme abgelenkt wird. Es zeigte sich, dass die Reaktion (die unbewusste, automatische Kompensation in der Stimmgebung) bei Ablenkung der Aufmerksamkeit vom Hören geringer war als ohne Ablenkung. Und dies betrifft eine rein physikalische Sprach-Eigenschaft, deren Wahrnehmung, wie das eingangs erwähnte Experiment von Colin Cherry gezeigt hat, weniger von der Aufmerksamkeit abhängig ist als das Verstehen der Wörter. Die Autoren der kanadischen Studie kommen zu dem Schluss, „dass Aufmerksamkeit erforderlich ist, damit das sprechmotorische Steuerungssystem optimalen Gebrauch von der auditiven Rückmeldung … machen kann“. Somit können wir folgendes annehmen:
Damit das Monitoring störungsfrei funktionieren kann, muss beim Sprechen die Aufmerksamkeit so verteilt sein, dass genug Wahrnehmungskapazität für das Hören und Verstehen der eigenen Rede eingesetzt wird.
Nehmen wir nun an, die Aufmerksamkeit ist im hinteren Bereich einer Sprecheinheit so stark von der Wahrnehmung der eigenen Stimme abgelenkt, dass keine phonologische Verarbeitung mehr stattfinden kann. Die auditive Rückmeldung wird in diesen Momenten nur noch als Geräusch verarbeitet, und die Sprachlaute werden nicht mehr als solche erkannt. Dann kann der Monitor das Ende der Sprecheinheit nicht mehr erkennen – die Einheit erscheint für den Monitor so, als wäre sie unvollständig artikuliert. Der Monitor stellt eine Nichtübereinstimmung, ein Mismatch zwischen Erwartung und Wahrnehmung fest, wie in 2.1. beschrieben, und unterbricht nach einer Reaktionszeit den Sprachfluss. Es würde sich also die folgende Ursachenkette für primäre Stottersymptome ergeben:
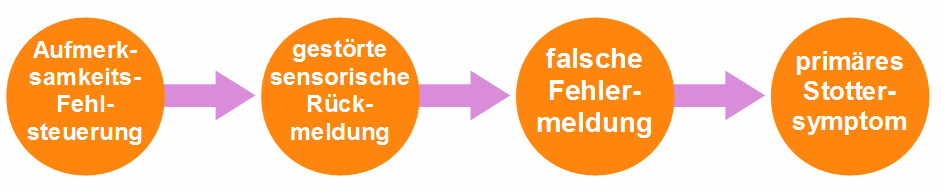
Abb.8: Ursachenkette für ein primäres Stottersymptom.
Es ist in diesem Zusammenhang wichtig, zu beachten, dass zwar das Sprachverstehen von der Aufmerksamkeit abhängig ist, nicht aber die Reaktion des Monitors auf Fehler: Das mit der Nichtübereinstimmung zwischen Erwartung und Wahrnehmnung verknüpfte Gehirnpotential (Mismatch Negativity) ist auch dann messbar, wenn die Aufmerksamkeit der Person von dem verbalen Stimulus abgelenkt ist [5] (mehr...) . Ich nehme deshalb an, dass Störungen der auditiven Rückmeldung – die Hauptursache für das Stottern innerhalb gebundener Sprache – dadurch verursacht werden, dass der Sprecher seine Aufmerksamkeit an den Enden von Sprecheinheiten zu stark vom Hören abzieht.
Es wurde bereits dargestellt, warum Störungen der auditiven Rückmeldung nur im hinteren, nicht jedoch im vorderen Bereich von Sprecheinheiten auftreten können: Im letzteren Fall könnten keine Erwartungen der korrekten Formen gebildet werden; das Monitoring wäre dadurch empfindlich gestört. Wenn das Monitoring funktionieren soll (sodass überhaupt Fehlermeldungen generiert werden können), kann die Aufmerksamkeit des Sprechers nur in den hinteren Bereichen der Sprecheinheiten vom Hören abgezogen sein. Mit anderen Worten: Der Monitoring-Mechanismus selbst erzwingt, dass an den Anfängen der Sprecheinheiten genug Wahrnehmungskapazität auf den auditiven Kanal gerichtet ist. Dieser Zwang besteht jedoch nicht in den hinteren Bereichen der Sprecheinheiten.
Doch warum sollte ein Sprecher in den hinteren Bereichen von Wörtern, Phrasen oder Sätzen seine Aufmerksamkeit vom auditiven Kanal abziehen? Warum sollte er dann seine eigene Stimme weniger wahrnehmen? Ich denke, dass der Sprecher zu diesem Zeitpunkt seine Aufmerksamkeit bereits auf die Planung der nächsten Einheit richtet, und zwar im Wesentlichen aus denselben Gründen, die schon im Abschnitt 2.2. genannt wurden: Zunächst deshalb, weil für Kinder in der Periode des Übergangs zum gebundenen Sprechen die Planung der Sätze eine neue Herausforderung darstellt, sodass am Ende eines Satzes die Aufmerksamkeit bereits auf die Planung des nächsten gerichtet ist. Später dann aus dem Bemühen, Stottern vorauszusehen und zu vermeiden. Wie ebenfalls schon im Abschnitt 2.2. ausgeführt, können,ungünstige Kommunikationssituationen, die zu einer übermäßig vorauseilenden Sprechplanung verleiten, zusätzlich zur Fehlverteilung der Aufmerksamkeit beitragen (mehr...) .
Gibt es empirische Nachweise dafür, dass Stotterer tatsächlich während des Sprechens zu wenig Aufmerksamkeit auf den auditiven Kanal richten? In mehreren Gehirn-Untersuchungen mit bildgebenden Verfahren (Brain Imaging) [8] zeigte sich, dass die auditiven Assoziationsareale auf der Großhirnrinde, die auch für das Monitoring verantwortlich sind, bei Stotterern während des Sprechens deutlich schwächer aktiviert waren als bei Nichtstotterern – zum Teil waren diese Regionen bei den Stotterern sogar deaktiviert. Außerdem war unter stotterreduzierenden Bedingungen wie z.B. Sprechen zum Takt eines Metronoms oder Lesen im Chor das flüssigere Sprechen mit größerer Aktivität in den auditiven Arealen der Großhirnrinde verbunden [9] (siehe auch Tabelle 1).
Darüber hinaus wurde in einer Meta-Analyse aus dem Jahr 2014 [10], in die alle bis dahin publizierten relevanten Brain-Imaging-Studien einbezogen wurden, festgestellt, dass (1) das Fehlen der Aktivierung in den sekundären Hör-Arealen während des Sprechens eines der charakteristischsten Merkmale des Hirnaktivierungs-Musters von Stotterern ist, und dass (2) nur die Hör-Areale beim flüssigeren Sprechen unter Bedingungen wie Metronom-Sprechen oder Lesen im Chor durchgängig stärker aktiviert waren. Zwar sind diese Resultate erst einmal nur Anzeichen für ein schlechtes Monitoring bei Stotterern – in diesem Sinn wurden sie auch von mehreren Forschern interpretiert (mehr) . Die Resultate sind kein direkter Nachweis für zu geringe Aufmerksamkeit auf den auditiven Kanal – man erinnere sich aber an die oben (im 4. Absatz) erwähnten Studien, in denen ein Zusammenhang zwischen der Aufmerksamkeit auf den auditiven Kanal und der Aktivierung der sekundären Hör-Areale gefunden wurde.
In einer Serie von EEG-Untersuchungen mit ereigniskorrelierten Potentialen [16] wurde außerdem festgestellt, dass Normalsprecher vor dem Sprechbeginn ihre Hörwahrnehmung modulieren (einstellen, gewissermaßen „auf Empfang schalten“). Diese Modulation vor dem Sprechen ist bei erwachsenen Stotterern deutlich schwächer oder fehlt ganz. Die Forscher vermuten, dass die Modulation dazu dient, das System optimal für die Verarbeitung der auditiven Rückmeldung einzustellen. Man kann diese Resultate wohl so interpretieren, dass Normalsprecher vor dem Sprechbeginn ihre Aufmerksamkeits-Verteilung so einstellen, dass genug Aufmerksamkeit auf den auditiven Kanal gerichtet ist. Natürlich tun sie dies unbewusst und automatisch. Bei Stotterern jedoch findet dieser Vorgang nicht oder in zu geringem Maße statt.
Interessant in unserem Zusammenhang ist auch das folgende Experiment, das an der Universität Utrecht mit stotternden Probanden durchgeführt wurde [7]: Nada Vasic und Frank Wijnen gingen von Hypothese aus, dass eine zu empfindliche Selbstkontrolle hinsichtlich normaler Sprechunflüssigkeiten und das Bemühen, diese normalen Unflüssigkeiten zu vermeiden, die primäre Ursache des Stotterns sei. Sie wollten deshalb untersuchen, ob durch die Ablenkung von der Selbstkontrolle des Sprechens das Stottern reduziert werden kann. Es wurden zwei Bedingungen getestet: erstens die Ablenkung von der Wahrnehmung des eigenen Sprechens überhaupt (durch ein Computerspiel) und zweitens die Ablenkung von der Wahrnehmung der Sprechflüssigkeit durch Fokussierung der Aufmerksamkeit auf den lexikalischen Aspekt der eigenen Rede – die Probanden mussten auf ein bestimmtes Wort achten (mehr) .
Es zeigte sich, dass die Ablenkung durch das Computerspiel zwar tatsächlich zu einer leichten Verminderung der Anzahl der Stotterblockaden führte, dass das Stottern aber viel stärker dann vermindert war, wenn die Probanden ihre Aufmerksamkeit auf den lexikalischen Aspekt der eigenen Rede richteten [6]. Die leichte Verminderung der Zahl der Blockaden durch die Ablenkung mit dem Computerspiel mag auf eine Ablenkung von der Stotter-Erwartung zurückzuführen sein, im Sinne der Anticipatory Struggle Hypothesis (siehe Abschnitt 3. 3.). Die stärkere Reduzierung der Blockaden beim Fokus auf dem lexikalischen Aspekt der eigenen Rede dürfte dagegen das Resultat einer verbesserten auditiven Rückmeldung der produzierten Laute und Wörter sein.
Als Mismatch-Negativity (MMN) bezeichnet man eine Komponente des ereigniskorrelierten Hirnpotentials (EKP), die nach ca. 100–150 ms als Reaktion auf einen unerwarteten Reiz auftritt, d.h. auf einen Reiz, der einer zuvor gebildeten Erwartung widerspricht. Die MMN ist also Ausdruck dafür, dass das Gehirn auf unerwartete Reize besonders stark reagiert – stärker als auf einen erwarteten Reiz. Eine MMN tritt auch dann auf, wenn ein erwarteter Reiz nicht kommt – wenn z.B. ein gleichmäßiger Rhythmus dargeboten wird und plötzlich ein Schlag fehlt.
Die Funktion dieses Reaktion des Gehirns besteht vermutlich darin, die Aufmerksamkeit auf Unerwartetes, womöglich Gefährliches zu lenken. Dementsprechend ist die MMN auch geeignet, die Aufmerksamkeit auf Fehler in Verhaltenssequenzen zu lenken: Verglichen mit dem erwarteten richtigen, erfolgreichen Verhalten ist der Fehler das Unerwartete, und das Gefährliche insofern, als ein Fehler stets mit irgendeiner Art von Nachteil oder Schaden verknüpft ist (sonst ist es kein Fehler). Daher ist dieses Verhalten des Gehirns, auf Unerwartetes besonders stark zu reagieren, die Basis des Sprach-Monitorings. Die MMN ist unabhängig von der Aufmerksamkeit; sie tritt sogar dann auf, wenn eine Versuchsperson stark vom Hören auf das Sprachsignal abglenkt ist durch eine Aufgabe, die sie zwingt, auf ein anderes. nonverbales Signal zu hören und bei Änderung dieses Signals einen Knopf zu drücken [7].
Es ist nun auch deutlicher, warum der Monitor echte Fehlermeldungen nicht von falschen unterscheiden kann: Der Monitor erkennt überhaupt keine Fehler, sondern er reagiert nur auf Unerwartetes, auf "trouble", wie Levelt es nennt. Die Reaktion des Monitors (die Unterbrechung des Sprachflusses) führt vielmehr dazu, dass der Sprecher die Aufmerksamkeit auf das richtet, was er gerade gesagt hat, und seinen Fehler erkennt (falls tatsächlich ein Fehler passiert ist).
Freilich widerspricht das unserer Alltagsüberzeugung: Wir glauben, dass wir unsere Rede unterbrechen, gerade weil wir einen Fehler bemerkt haben. Doch die Zeit, die vergeht, bis man die Unterbrechung des Sprachflusses wahrnimmt, dürfte länger sein als die Zeit, die benötigt wird, um den Sprechfehler zu erkennen: Im ersten Fall läuft die Information vom Gehirn an die Sprechmuskulatur und von dort zurück, im zweiten Fall ist nur ein Informationsabruf innerhalb des Gehirns nötig.
(zurück)
Charles van Riper berichtet den folgenden Fall: Einer seiner Therapiepatienten war ein Junge, der stark zu stottern begonnen hatte, nachdem seine Mutter gestorben war und der Vater eine neue Frau ins Haus geholt hatte. Van Riper bekam schließlich heraus, dass diese den Jungen systematisch schikanierte und konnte den Vater davon überzeugen, sich wieder von der Frau zu trennen. Nachdem die „böse Stiefmutter“ aus dem Haus war, verschwand bei dem Jungen das Stottern nach kurzer Zeit fast völlig [6]. Man kann sich denken, dass der Junge in der Kommunikation sowohl mit der Stiefmutter als auch mit dem Vater (der diese Frau womöglich geliebt hat) stark verunsichert war: dass er sich genau überlegt hat, was er ihnen sagt, und dass er während des Sprechens ängstlich ihre Reaktionen beobachtet hat.
(zurück)
Die Versuchspersonen mussten in freier Rede den Inhalt eines zuvor gelesenen Zeitungsartikels wiedergeben. Um die Aufmerksamkeit von der Wahrnehmung der eigenen Sprache insgesamt abzulenken (Versuchsbedingung 1), mussten die Teilnehmer während des Sprechens das Computerspiel „Pong“ spielen (in zwei Schwierigkeitsgraden). Um die Aufmerksamkeit speziell von der Wahrnehmung der Unflüssigkeiten im eigenen Sprechen abzulenken (Versuchsbedingung 2), sollten die Teilnehmer auf die Wörter, die sie produzierten, hören und jedesmal, wenn das Wort „die“ vorkam, einen Knopf drücken. Die Sprache der Teilnehmer war Niederländisch; "die" bedeutet "jener/jene".
(zurück)
„Linke superior-temporale Aktivierungen, die bei den Kontrollprobanden beobachtet und mit dem Self-Monitoring in Zusammenhang gebracht wurden, fehlten anscheinend während des Stotterns. Deaktivierungen während des Stotterns waren ebenfalls charakteristisch. Nicht nur, dass der linke obere Temporalkortex nicht aktiviert war – der linke posteriore Temporalkortex (BA22) zeigte signifikante Deaktivierungen [im Vergleich zur Ruhebedingung – T.H.], die bei den Kontrollprobanden nicht zu sehen waren. […] Das neuronale System des Stotterns schließt […] das Fehlen der normalen 'Self-Monitoring'-Aktivierung ein...“ [11]
„...unsere Ergebnisse lassen vermuten, dass Stotterer, wenn sie unflüssig sind, ihre Sprachproduktion nicht in derselben Weise effektiv beobachten wie die Kontrollprobanden. Vielleicht ist eine Unfähigkeit, die eigene Spontansprache kontrollierend wahrzunehmen, mit der Produktion gestotterter Sprache in irgendeiner Weise verknüpft.“ [12]
„…eine weitaus größere Zahl von Regionen, die an der Selbstwahrnehmung von Sprache und Stimme beteiligt sind, waren unter den stotterreduzierenden Bedingungen stärker aktiv als unter den stotterverstärkenden Bedingungen. sowohl bei den Stotterern als auch bei den Kontrollprobanden. Diese Regionen umfassen, in der rechten und linken Hirnhälfte, anteriore und posteriore auditorische Assoziationsareale... […] … der direkte Vergleich der Reaktionen von Stotterern und Kontrollprobanden lokalisiert sehr genau eine Reihe von Regionen, in denen die stotterreduzierenden Bedingungen eine deutlichere Reaktion bei den Stotterern auslösen. Diese umfassen den anterioren MTG und den anterioren STG – Regionen, die speziell bei Stimmen und verstehbarer Sprache aktiviert zu werden scheinen – was nahe legt, dass die stotterreduzierenden Bedingungen die Selbstwahrnehmung der Stotterer in einem höheren Grad verstärken als die der Kontrollprobanden.“ [13]
(zurück)